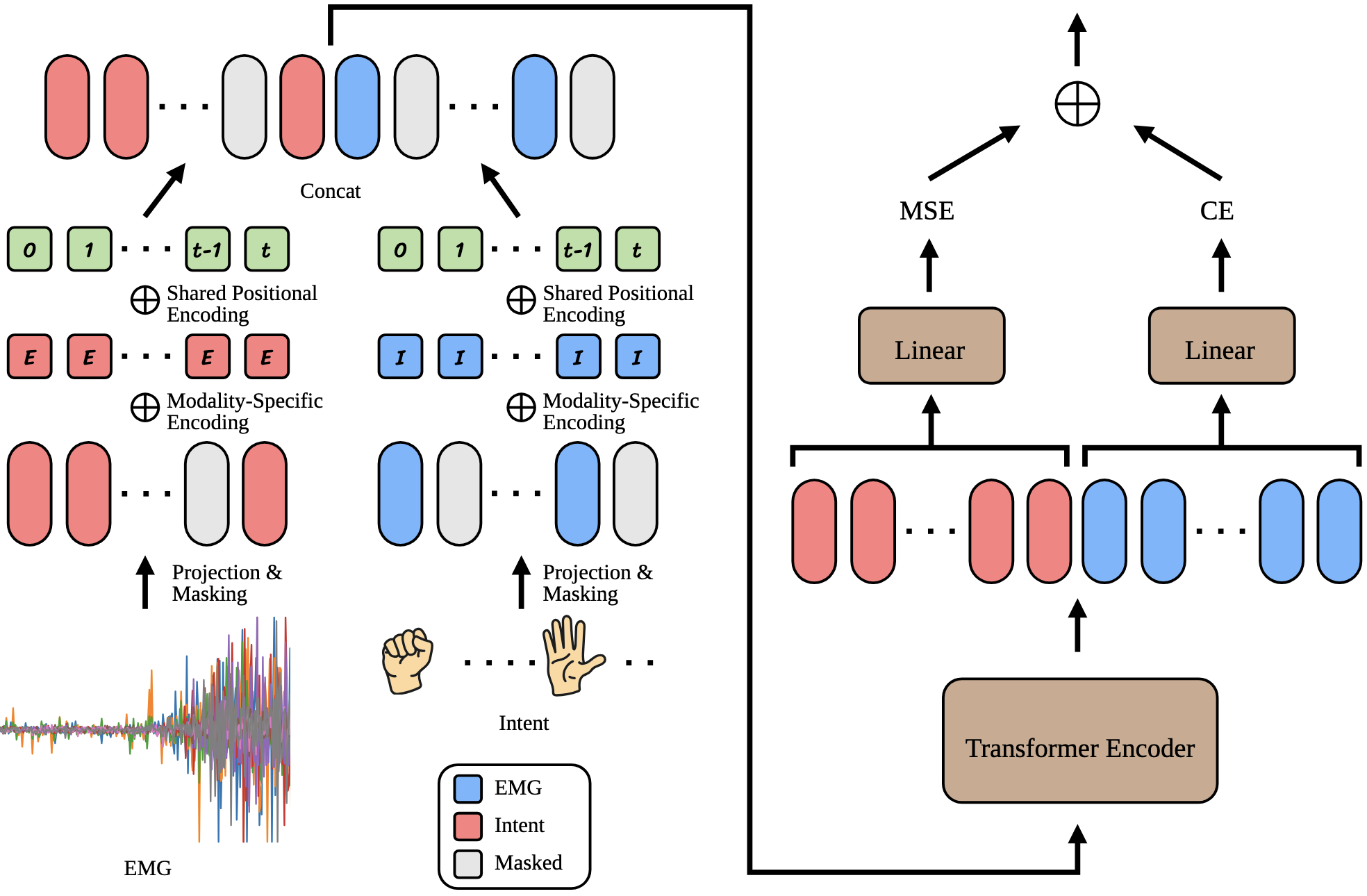
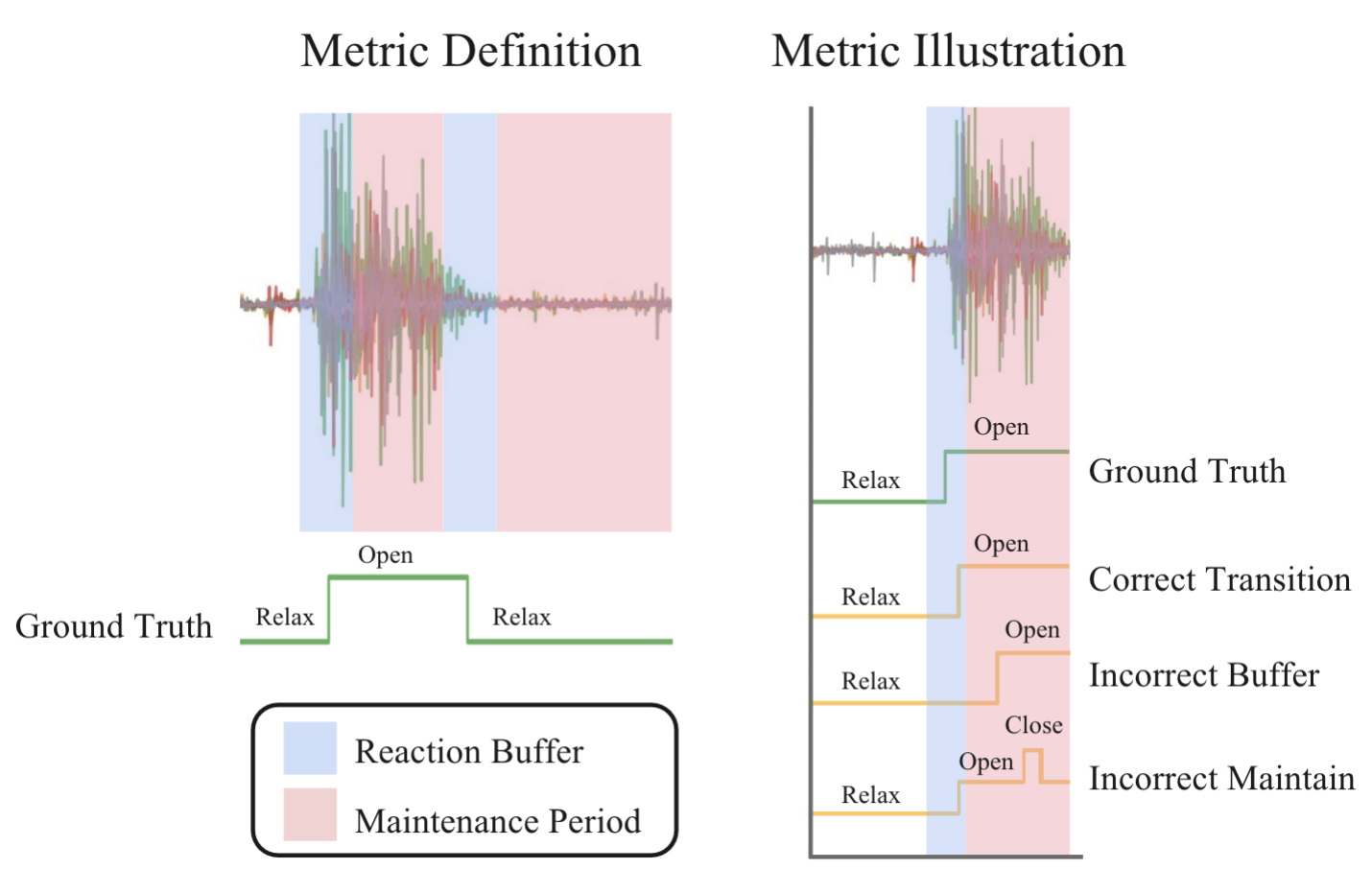
Intent Detection Examples
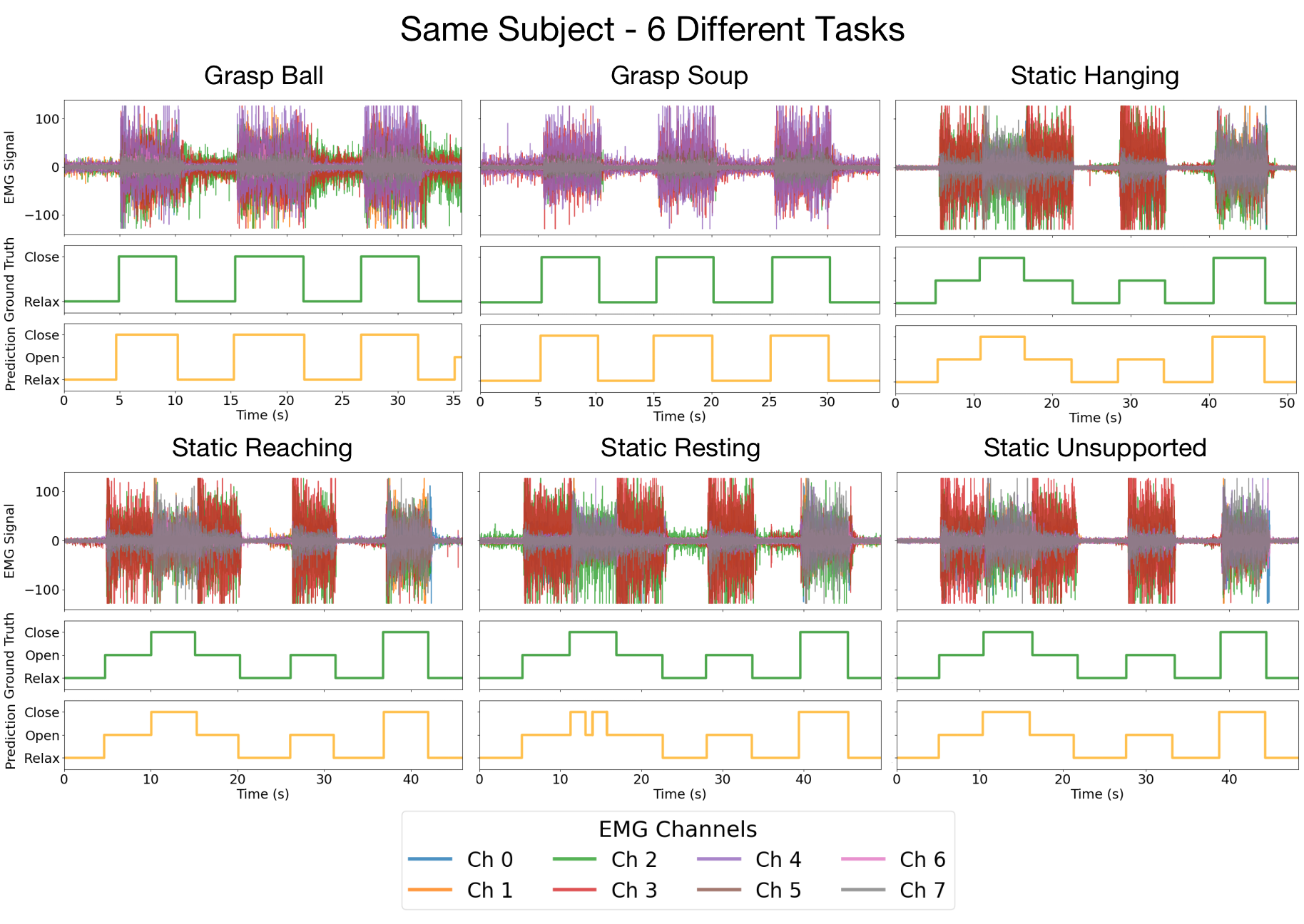
(1) Same Subject, Different Task. On a new, unseen subject, ReactEMG accurately detects open and
close intents across diverse real-world tasks that contain different arm movements.
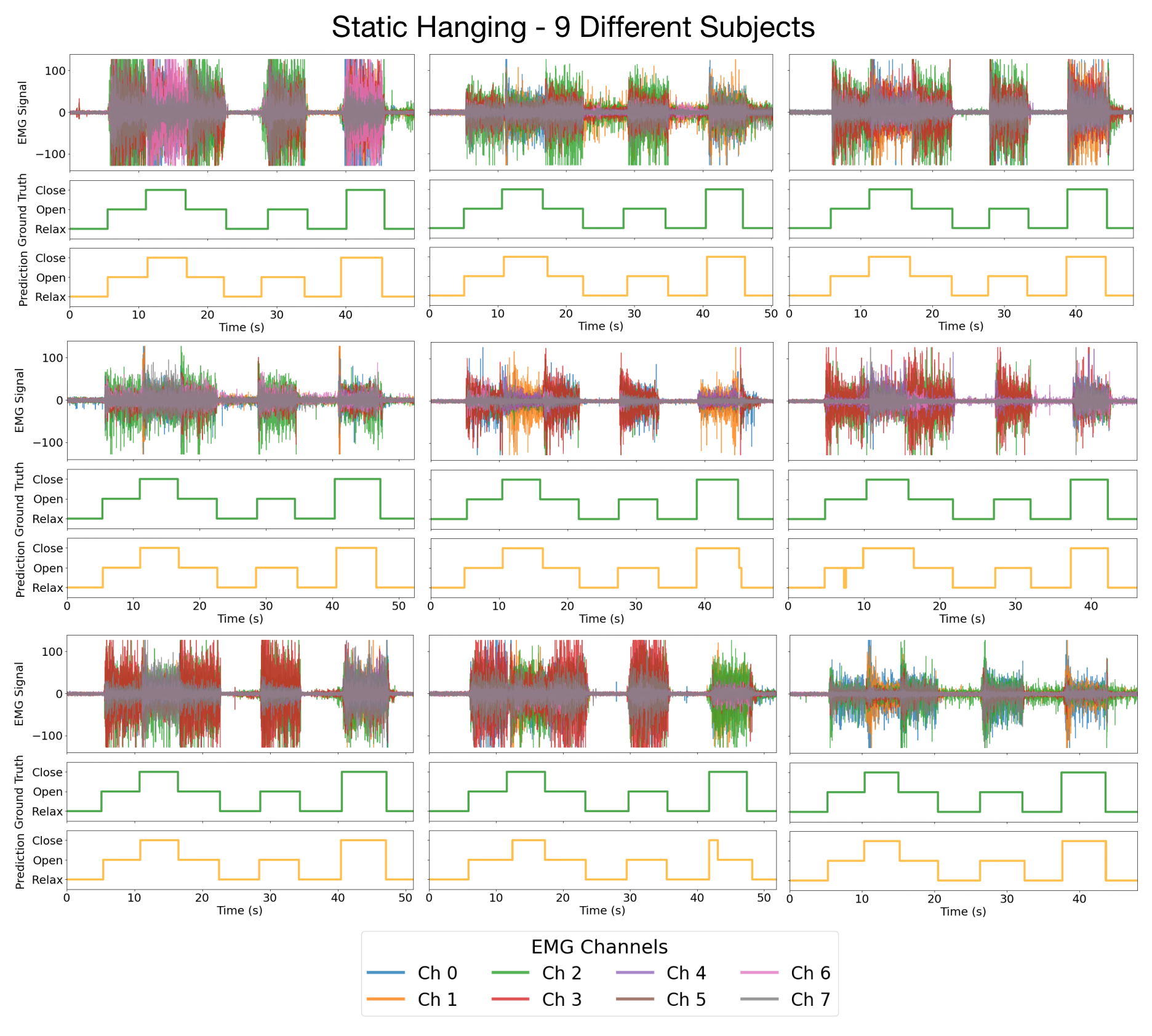
(2) Same Task, Different Subjects. In the static hanging task (subjects perform open and close
gestures with the arm hanging freely at the side) ReactEMG accurately detects intents across different
subjects, even when EMG signals exhibit vastly different coactivation patterns.